Array.from(document.querySelectorAll('.roster__players .roster-card-item'), el => {
const id = '';
const name = el.querySelector('.roster-card-item__title-link').innerText;
const year = el.querySelectorAll('.roster-player-card-profile-field__value')[1].innerText;
const height = el.querySelectorAll('.roster-player-card-profile-field__value')[0].innerText;
const position = el.querySelector('.roster-card-item__position').innerText;
const hometown = el.querySelector(".roster-player-card-profile-field__value--hometown").innerText;
hs_el = el.querySelector(".roster-player-card-profile-field__value--school");
const high_school = hs_el ? hs_el.innerText : '';
ps_el = el.querySelector(".roster-player-card-profile-field__value--previous_school");
const previous_school = ps_el ? ps_el.innerText : '';
const jersey = el.querySelector(".roster-card-item__jersey-number").innerText;
const url = el.querySelector("a")['href'];
return {id, name, year, hometown, high_school, previous_school, height, position, jersey, url};
})Last year some students of mine at Maryland and I worked to produce a comprehensive set of data on women’s college basketball rosters, and while that process involved a lot of manual effort on top of a base of Python scrapers, it also got me thinking: how hard would it be to extend that system to other sports? As it turns out, it wasn’t that hard, which is why today I’m happy to announce the release of comprehensive roster data for women’s college volleyball for the 2023 season.
There are more women playing volleyball than basketball at the college level, thanks to teams that are slightly larger than many basketball teams and the proliferation of teams. We’ve collected more than 920 teams’ rosters, accounting for more than 15,800 players. Texas and Ohio provide the most players per capita, which was somewhat surprising to me given that Texas has so many people. It also has a lot of colleges that play volleyball. Alexa Henry, a graduate student at UMD, spent some time digging into this data and found that Texas is a leading exporter of players, too: even though the state has 49 NCAA volleyball teams, more than 1,630 Texans are on rosters across the nation. At an average of 17 players on each team, Texas players alone could populate nearly 96 entire teams.
The first step in collecting this data was to take the Python scrapers I wrote for basketball rosters and point them towards volleyball rosters. Most universities use the same software for all of their teams, so it was mostly a matter of developing a list of team URLs. The first time I ran the volleyball scrapers they yielded nearly 12,000 players, which I estimated to be about 80 percent of the total number. I made one big change to help retrieve the remainder: incorporating Simon Willison’s excellent shot-scraper library.
Ostensibly a tool for taking automated screenshots, shot-scraper also (as its name suggests) has a useful ability to scrape websites, and in particular ones where JavaScript makes traditional scraping more annoying. College roster pages are a good example of this, because they often fetch JSON after page load. That doesn’t mean you can’t use the traditional requests + BeautifulSoup pattern, but with shot-scraper you can execute JavaScript against the page, and that comes in very handy.
Here’s an example: the San Jose State roster. It’s a fairly typical example of what college team roster pages look like:
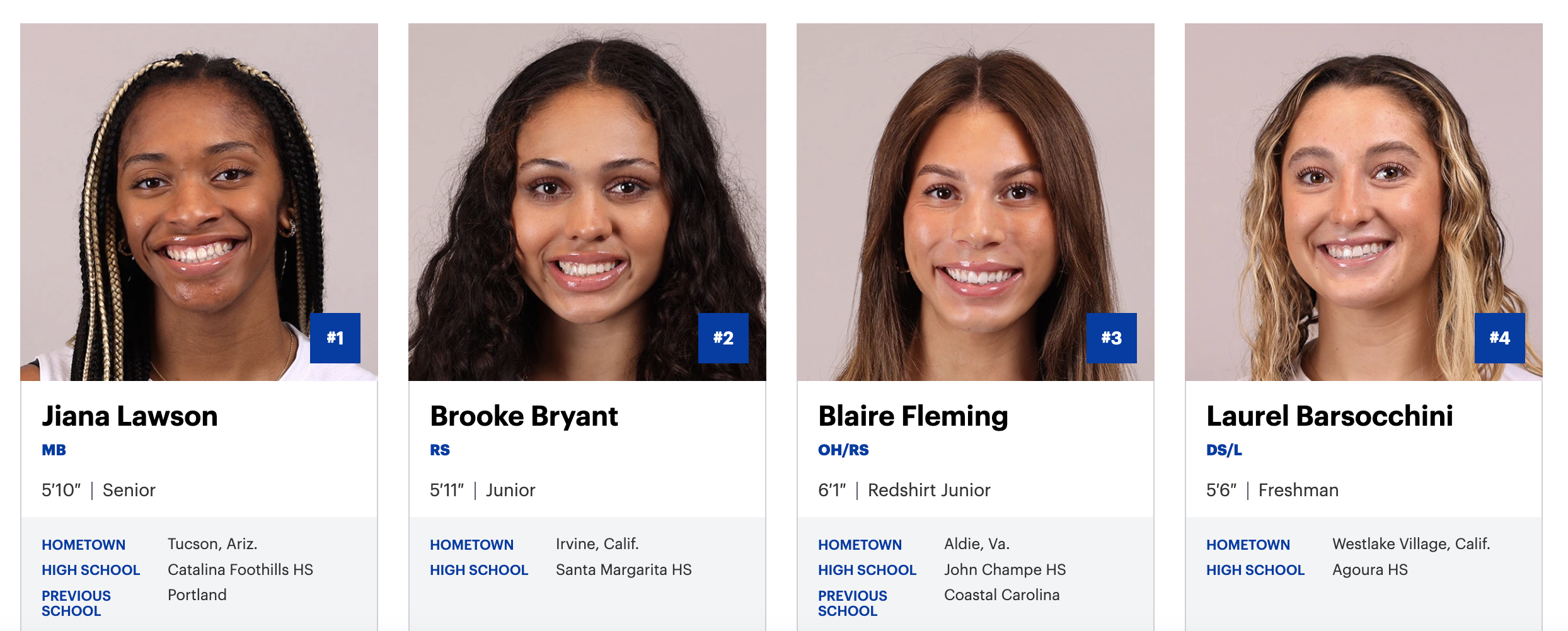
What we want from this page is a JSON array of player objects based on the HTML attributes in the source. Skipping HTML parsing and heading straight to grabbing objects from the DOM makes things easier. Given access to the page, here’s the JavaScript that does it:
That, plus a little post-processing, produces an array that looks like this (this version is truncated):
[{'id': '', 'name': 'Jiana Lawson', 'year': 'Senior', 'hometown': 'Tucson, Ariz.', 'high_school': 'Catalina Foothills HS', 'previous_school': '', 'height': '5′10″', 'position': 'MB', 'jersey': '#1', 'url': 'https://sjsuspartans.com/sports/womens-volleyball/roster/season/2023/player/jiana-lawson', 'team_id': 630, 'team': 'San Jose State', 'season': '2023'}, {'id': '', 'name': 'Brooke Bryant', 'year': 'Junior', 'hometown': 'Irvine, Calif.', 'high_school': 'Santa Margarita HS', 'previous_school': '', 'height': '5′11″', 'position': 'RS', 'jersey': '#2', 'url': 'https://sjsuspartans.com/sports/womens-volleyball/roster/season/2023/player/brooke-bryant', 'team_id': 630, 'team': 'San Jose State', 'season': '2023'}]The function for San Jose State is here. It’s not fancy, but it doesn’t need to be. The good news is that shot-scraper can accept pretty much any JavaScript: a ternary operator, string functions, etc. The bad news is that some of these sites have so much JavaScript running on them that it can get a little fussy.
This doesn’t make scraping one-click simple, a task that AI will probably hasten in most cases. But it does reduce the amount of time I spend wrestling with weird HTML and JS interactions, and it has made it possible for me to gather even more teams’ rosters, cutting down on the manual work needed for this effort. It allows me to ask: what other sports can I collect rosters from?